

The Declarative Mindset
I’m going to wax poetic on the virtues of declarative thinking within the IT industry. Along the way we will go over some definitions and introduce the pseudo-declarative manifest and how it can add value to a project.
Introduction
Within the IT industry there are often dozens of avenues an IT professional can pursue to get to the same arbitrary goal. One can categorize those solutions as either imperative or declarative in their approach. Most modern projects implement both imperative and declarative solutions in their overall pipeline.
What is Imperative?
It is easier to start with imperative as concept as every single IT solution eventually boils down to imperative code written to accomplish a task. If you are a programmer of backend systems coding business logic you may code out the solution in java imperatively going over every bit of logic in your module. You are commanding the system to do your bidding using whatever twisted programming logic you weave into it with your wizard-like skills. If you program in Go or any other language that interprets or compiles to some executed action on a computer system then you are living in the abundant land of imperative where you are limited only by your imagination and grit.

What is Declarative?
Declarative and imperative thinking compliment one another. In many ways, declarative is simply an abstraction of imperative commands.
Following the same example, you may also deploy the versioned binary artifact (jar in this case) to an artifactory and built in a docker image which is then released to various Kubernetes environment using declarative YAML. Perhaps you even have infrastructure as code declarative manifests that are used to build out the kubernetes environments that the code gets deployed within. These are declarative as the manifests are written in a manner that defines the final state of a thing. This manifest then gets fed into an engine that makes the desired state into a reality.
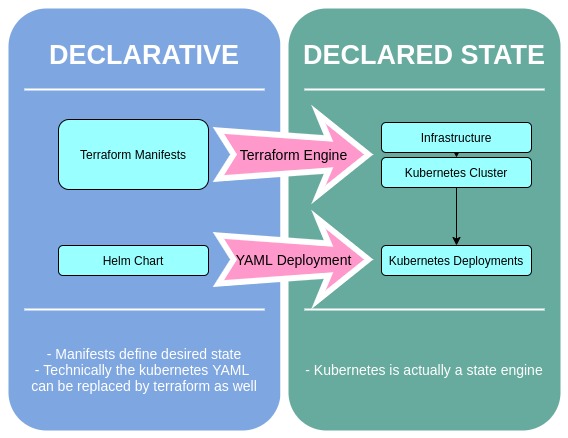
Semi-Declarative?
Often, the lines between what is declarative vs. imperative is not extremely clear or is a matter of context. Taking the prior example a step further, the pipeline as code you may use to build and deliver your project workload could be written as a YAML file such as .gitlab.yml or azure-pipeline.yaml. This pipeline code is usually stitched together via bash or PowerShell scripts which is imperative by nature. A properly defined library of loosely coupled shared pipeline as code tasks can lead to a very declarative downstream pipeline as code manifest. But due to the many freedoms of pipline as code, it becomes very easy to let imperative coding bleed into what should be a declarative endeavor.
NOTE I also consider breaking out of the Terraform engine to run elaborate system scripts via null_resources an imperative perversion of a declarative manifest.
Pseudo-Declarative
As I look for more ways to be declarative in my solutions, I’ve been constructing something I’ve been calling the pseudo-declarative manifest. This is just a YAML formatted manifest that could be used to apply a known or fictional state within a project if you had an engine to apply it. Basically, you create declarative manifests that don’t have an engine.
I encourage teams to create declarative manifests for their projects, even if they don’t actually do anything. Here are a few declarative manifests which can immediately return value;
- A manifest that covers all the repos, branches, and pipelines that comprise the entirety of the project.
- A manifest that outlines all the inputs required for other teams or upstream processes to consume your project.
- In a microservice or batch deployment, A manifest declaring the dream state of deployment for a workload (this can get quite involved with say Spark Streaming jobs as I will show in example 1)
In some cases, you may even be able to justify writing your own declarative engine for your made up manifests. When that time comes, you will have created your own structural foundation for your coding efforts. I have done this for complex data science driven or ephemeral workload pipeline as code. A pseudo-declarative manifest can be as elaborate as required but it is good to lean towards terseness and self-describing language where possible.
Example 1 - Spark Streaming Workload
Here is an example of a declarative manifest that declares how 2 spark streaming jobs will be delivered into an environment.
---
deployment:
dryrun: False
suppress_output: False
default_batch_type: k8s
schedule_timeout: 120
delete_timeout_seconds: 120
exception_email_recipients: False
# All standard spark jobs to k8s will use this template of values
# (unless otherwise defined individually)
_k8s_batch:
default_values:
args: []
description: Spark 2.4 Streaming Job
enabled: true
class: com.company.project.job
namespace: sparkstreamjobs
containerimage: projectname.azurecr.io/spark-stream
drivermemory: 1024m
numexecutors: 2
executormemory: 512m
executorcores: .1
jarpath: local:///opt/spark/jars
jar: projectname-assembly-1.0.jar
deploy-mode: cluster
config:
- "spark.kubernetes.submission.waitAppCompletion=false"
- "spark.kubernetes.driver.annotation.prometheus.io/scrape=true"
- "spark.kubernetes.driver.annotation.prometheus.io/port=8088"
- "spark.driver.extraJavaOptions=-javaagent:/prometheus/jmx_prometheus_javaagent-0.11.0.jar=8088:/etc/metrics/conf/prometheus.yaml"
- "spark.metrics.conf=/etc/metrics/conf/metrics.properties"
- "spark.network.timeout=800"
- "spark.sql.broadcastTimeout=1200"
- "spark.sql.streaming.metricsEnabled=true"
envvars:
- SCALA_ENV
- CHECKPOINT_ACCOUNT_NAME
- CHECKPOINT_ACCOUNT_KEY
- CHECKPOINT_CONTAINER_NAME
- CHECKPOINT_PATH
- KAFKA_BOOTSTRAP_SERVERS
- STORAGE_ACCOUNT_NAME
- STORAGE_ACCOUNT_KEY
- STORAGE_PATH
- JDBC_URL
- JDBC_DRIVER
- CASSANDRA_USERNAME
- CASSANDRA_PASSWORD
- CASSANDRA_URL
batches:
- class: com.company.project.job
jar: projectname-assembly-1.0.jar
args:
- arg1
- class: com.company.project.job
jar: projectname-assembly-1.0.jar
args:
- arg2
This example is a little advanced as it contains self describing code blocks for default values of a particular job types which are also included in the manifest. In this example k8s batch types are the default and use _k8s_batch.default_values for default values. The batches section gets created in the engine as individual jobs with unique names comprising of the class and args block to construct the final spark submit command to a kubernetes cluster. If a developer wanted to add a new job that bumps up the executor cores they need only update the individual batch element with the override values.
batches:
- class: com.company.project.job
jar: projectname-assembly-1.0.jar
args:
- arg1
- class: com.company.project.job
jar: projectname-assembly-1.0.jar
args:
- arg2
- class: com.company.project.job
jar: projectname-assembly-1.0.jar
namespace: specialsparkstreamjob
executorcores: .4
config:
- "spark.kubernetes.submission.waitAppCompletion=true"
- "spark.kubernetes.driver.annotation.prometheus.io/scrape=false"
- "spark.metrics.conf=/etc/metrics/conf/metrics.properties"
- "spark.network.timeout=800"
- "spark.sql.broadcastTimeout=1200"
args:
- specialJob
I wrote a python app to consume this manifest and create the appropriate spark submit commands. This could also have been done in more modern YAML manifests with the spark-operator project.
Example 2 - Something As A Service
A less esoteric example would be laying out all the requirements that it would take to onboard a development team to a shared vault infrastructure for their project in an organization. It is easy to think about this in terms of a single service. But the vault service can be consumed in any number of ways. What this manifest may look like for one organization or team may be completely different than another.
I find that laying out an example fictional project manifest helps quite a bit either way. Here is an example for onboarding a project that requires github integration, 3 key value mounts, 1 appRole with access to generate an AWS dynamic STS credential, JWT roles for management of the vault secrets, and JTW roles for the server portion of the project app to use that requests the approles for the agent portion of the app.
This sounds pretty complex but if you think of it all declaratively, this all maps out very nicely.
## Standard information
project: teamproject
team: Team1
owner: Project Owner
environments:
poc:
version: '0.1.0-poc'
dev:
version: '0.1.0-dev'
int:
version: '0.1.0-int'
prod:
version: '0.1.0'
## All the features this project will use
features:
# KV Stores used for this project
kv:
teamproject_app_pipeline:
path: teamproject/app/pipeline
teamproject_app_config:
path: teamproject/app/config
teamproject_app_agent:
path: teamproject/app/agent
github:
# Github integrations
myOrg:
teamproject_repo:
sts:
# AWS STS secret generation for a particular role.
teamproject_agent_access:
aws_role_arn: myawsrole
approle:
teamproject_server:
policies:
- kv.teamproject_app_config.readonly
- kv.teamproject_app_agent.full
- sts.teamproject_agent_access
token:
# Setup a default policy token for unwrapping at the agent end
unwrap:
policies:
- default
# Setup a token policy for generating wrapped tokens
app_server:
policies:
- kv.teamproject_app_config.readonly
- kv.teamproject_app_agent.readonly
## And the roles required to use them
roles:
## Pipeline access to vault components
teamproject_app_pipeline:
env: [poc, dev, int, prod]
type: github
target: myOrg.teamproject_repo
policies:
- kv.teamproject_app_pipeline.readonly
- kv.teamproject_app_config.readonly
- approle.teamproject_server
- token.unwrap.create
## Team owners access to manage components in nonprod
teamproject_admins_nonprod:
env: [poc, dev, int]
type: jwt # could be for Azure AD integrated authentication
group: TeamProject_Admins_NonProd
policies:
- kv.teamproject_app_pipeline.full
- kv.teamproject_app_config.full
- kv.teamproject_app_agent.full
- token.unwrap.full
- token.app_server.full
teamproject_admins_prod:
env: [poc, dev, int, prod]
type: jwt
group: TeamProject_Admins_Prod
policies:
- kv.teamproject_app_pipeline.full
- kv.teamproject_app_config.full
## The app service access to the vault components (in this case the app is integrated with vault)
teamproject_server_poc:
env: poc
type: jwt
group: TeamProject_Server_poc
policies:
- kv.teamproject_app_config.readonly
- kv.teamproject_app_agent.full
- approle.teamproject_agent
- token.app_server.full
teamproject_server_dev:
env: dev
type: jwt
group: TeamProject_Server_dev
policies:
- kv.teamproject_app_config.readonly
- kv.teamproject_app_agent.full
- approle.teamproject_agent
- token.app_server.full
teamproject_server_int:
env: int
type: jwt
group: TeamProject_Server_int
policies:
- kv.teamproject_app_config.readonly
- kv.teamproject_app_agent.full
- approle.teamproject_agent
- token.app_server.full
teamproject_server_prod:
env: prod
type: jwt
group: TeamProject_Server_prod
policies:
- kv.teamproject_app_config.readonly
- kv.teamproject_app_agent.full
- approle.teamproject_agent
- token.app_server.full
In this example we can infer that;
- We have 4 environments, each running a specific tagged version of the app
- We expect to have 3 key value secret mounts per environment, one for app config, one for the pipeline, and a last one for the app agent
- Access policies will be auto-generated as part of the kv mount allocation and later assigned to the defined roles
- An auth group for the team owners will be created and assigned access to most of the created resources
- The project app apparently consists of a server and an agent wherein the server portion manages secrets in a kv store that the agent can later access.
- The app server role (‘teamproject_server’) apparently uses a service account to authenticate with and likely generates a wrapped token for the agents which has access to the kv store where the server service updates secrets.
What is not shown here are any outside dependencies that fall outside the realm of the vault team’s abilities to deploy. In this case there is also a backend database dependency that the server uses to pass wrapped tokens to the running agent portion of the app. This is why you would see a different role being created per environment but with different group names (AD service accounts having been generated ahead of time against the same AD forest).
While these examples are not using HCL or anything beyond simple YAML you can begin to see how using a manifest like this can really help to unearth what development efforts are required to turn a project into a fully consumable ‘as a service’ pipeline for other business units. It would be conceivable to use such manifests within upstream projects and include downstream Gitlab runners that apply the manifest. Or simply keeping one central vault project repo that teams PR into for centralized configuration as code of vault access.
NOTE This is just one example of some of vault services being consumed in a moderately complex application and pipeline. It would be conceivable to have multiple service profile examples of these kinds of manifests for various project requirements.
Conclusion
If I could make everything I work on a declarative manifest I think I would. It is a valuable tool to have even if you don’t have the engine to process the desired state. Before asking me, I’ll say that I’ve yet to find the perfect parsing engine for declarative manifest processing. Terraform is great when you are able to use it, Helm makes kubernetes deployments more sanely declarative as well. But neither could be used in the examples I’ve laid out. I welcome ideas for general use tools for such things though. If you know of any please reach out to me on LinkedIn or Twitter.