

Kubernetes App Deployments with Terraform
Deploying applications via the kubernetes terraform provider is a viable solution for some workloads.
Introduction
Admit it, at one point you may have attempted to get a kubernetes application deployment working with Terraform, got frustrated for one of many reasons and gave up entirely on using the tool in favor of other, less finicky solutions. That is exactly what I did at least. Well that was then and now is now. Multiple updates to both the helm and kubernetes providers have been done so maybe it is time to re-evaluate how you can use Terraform for deploying some of your workloads.
Usage
It is fairly common to see managed kubernetes cluster deployments being done with the venerable infrastructure as code tool, Terraform. Jenkins-x will even create cloud specific terraform manifests to stand up new environment clusters. These deployments are driven by cloud specific terraform providers which are maintained and updated via their respective cloud owners. For a primer on how to deploy a managed cluster for one of the three ‘big clouds’ you can hit up their resource documentation and find examples online. I’ll not cover that aspect of the deployment but here are some good starting points:
- Azure: AKS Terraform Resource
- AWS: EKS Terraform Resource
- Google: GKE Terraform Resource
What is less commonly talked about is using the terraform kubernetes provider afterwards to deploy custom workloads. Usually, once the initial cluster is constructed, the deployment of workloads into the cluster tend to fall to other tools of the trade like helm, helmfile, kustomize, straight YAML, or a combination of one or more of these technologies. Kuberentes is just a state machine with an API after all right?
In this article I’m going to go down the rabbit hole of how one can use terraform to not only deploy the cluster, but also to setup initial resources like namespaces, secrets, configmaps, and put them all into a deployment via the kubernetes provider. And we will do this all with a single state file and manifest.
NOTE: We can also do custom helm deployments via the helm provider but that is not the purpose of this exercise.
Here is the obligatory diagram showing some component parts of a multiple part deployment into kubernetes.
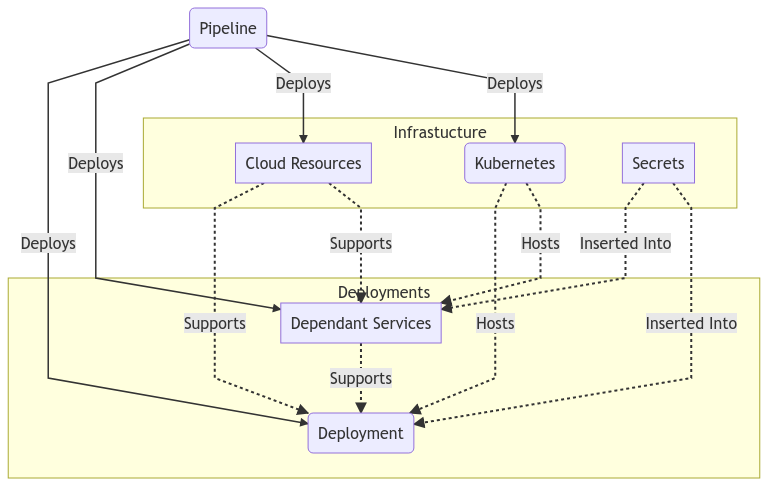
A multi-part kubernetes deployment
Why and When
Why would you want to do such a thing? Well I’m glad I asked myself that question very loudly and with a slight tone of derision to my voice. Honestly, you likely don’t want to do this, at least for every project. But there are some sound reasons. My reasons were fairly nuanced. I needed to quickly convert a custom kubernetes deployment into a pipeline that would fully stand up a Kuberentes cluster with the deployment so it could be run on-demand and shutdown after it was done processing.
- There is a need to take some snowflake kubernetes cluster app and turn it into a pipelined deployment for multiple environments.
- You must be able to ensure that a deployment state is always the same.
How - Part 1
In my case I already had a bespoke deployment running in a cluster that I needed to mimic. So I used an existing tool that was able to generate a good deal of the Terraform starting manifest automatically. It turned a manual slog into a fairly rapid affair. The tool is called k2tf and it will convert kubernetes yaml into terraform. This is a great starting point and I recommend you start here if your situation allows.
How - Part 2
The terraform kubernetes provider exposes most of the attributes of the resources it generates via the metadata of the resource. This makes chaining your resource dependencies very easy. Lets look at a partial example that I’ve pared back here for brevity sake.
resource kubernetes_namespace deployment {
metadata {
name = var.namespace
}
}
// Example Secrets to expose as env vars in deployment
resource kubernetes_secret appsecrets {
metadata {
name = "appsecrets"
namespace = kubernetes_namespace.deployment.metadata.0.name
}
type = "Opaque"
data = {
ACCOUNT_KEY = var.account_key
}
}
// Example configmap settings to expose as env vars in deployment
resource kubernetes_config_map settings {
metadata {
name = "appconfig"
namespace = kubernetes_namespace.deployment.metadata.0.name
}
data = {
SOMEPATH = "/root/why/is/this/parameterized"
APPNAMESPACE = kubernetes_namespace.deployment.metadata.0.name
CLOUDSERVICE = "Azure"
ACCOUNTNAME = var.account_name
APPNAME = var.kubernetes_app_name
}
}
resource kubernetes_deployment app {
metadata {
name = var.kubernetes_app_name
namespace = kubernetes_namespace.deployment.metadata.0.name
labels = {
app = var.kubernetes_app_name
}
}
spec {
replicas = 1
selector {
match_labels = {
app = var.kubernetes_app_name
}
}
template {
metadata {
labels = {
app = var.kubernetes_app_name
}
}
spec {
container {
name = var.kubernetes_app_name
image = "${var.container_registry}/${var.image}:${var.image_tag}"
command = var.container_command
// This is a configmap to envvar setup
env_from {
config_map_ref {
name = kubernetes_config_map.settings.metadata.0.name
}
}
// And a secret to envvar setup
env {
name = "ACCOUNT_KEY"
value_from {
secret_key_ref {
name = kubernetes_secret.appsecrets.metadata.0.name
key = "ACCOUNT_KEY"
}
}
}
resources {
requests {
memory = var.kubernetes_pod_memory
}
}
termination_message_path = "/dev/termination-log"
image_pull_policy = "Always"
}
restart_policy = "Always"
termination_grace_period_seconds = 30
dns_policy = "ClusterFirst"
}
}
strategy {
type = "RollingUpdate"
rolling_update {
max_unavailable = "1"
max_surge = "1"
}
}
revision_history_limit = 10
}
}
As you can see, we create the namespace, a secret, a configmap, and connect them all to a deployment. I purposefully included the config map in this deployment as it was rather hard to find an example of one in action via terraform HCL.
For a fuller example of a terraform deployment in tandem with an Azure AKS cluster check out my repo. I include some additional nuances around permissions that are also rather difficult to find for whatever reason.
Possible Issues
-
Using the kubernetes provider is considered a faux pas in terraform land when used alongside a cluster deployment. This is usually due to provider dependency issues (because terraform providers don’t adhere to any kind of dependency rules). Because of this, it is recommended to do deployment and cluster construction in separate manifests and thus, separate state databases. We work around this mostly by the way we configure the provider to eat output from the cluster creation resource. This may lead to race conditions and other issues if not carefully managed.
-
As with the kubernetes provider, the same is true for the helm provider. We may have to run the terraform apply multiple times to get the deployment to go through if you decide to implement a helm chart concurrently. Moreso, when using Azure ACR as helm private repositories it seems. These private repos seem to have an abysmally short lived authentication token that can time out well before the cluster has been created. This will mean that the helm deployment is likely to not find the chart when it comes time to actually deploy it. You can get around this by including custom helm charts local with the deployment or with carefully crafted null_resource scripts to run azure cli commands and depends_on constructs.
-
From my experience, cluster destruction takes far longer than construction. My theory is that all the resource finalizer annotations that cloud providers like to force upon us cause the destruction of resources to hang to the point of hitting some kind of internal cloud provider timeout. That’s just my personal theory though. Obviously your experiences may vary.
Kubernetes finalizers are the hidden WTF?!?! of resource redeployments. Be aware that they exist, that some operators like to use them, that some cloud providers will use them, and that they can and will prevent you from deleting or redeploying resources in your clusters. Know how to clear them out in a pinch.
Conclusion
While Terraform may not be the best solution for maintaining state in kubernetes clusters with fluctuating workloads (where you may not have an expected state from day to day), it is a perfectly sound solution for known workloads and can be easily adopted for use in ephemeral cluster deployments.